Es común observar que estos dos términos suelen confundirse, lo cual puede generar inquietudes entre nuestros usuarios. En esta entrada, aclararemos en qué consiste una migración y cómo llevar a cabo una transferencia de dominio para brindarte una comprensión completa de estos procesos.
Diferencia entre dominio y hosting
Primero debemos conocer el significado de estos dos términos fundamentales dentro del ámbito de los servicios de alojamiento web. Por su parte, el dominio es el nombre de nuestro sitio web; es decir, un “www”. Este, a su vez, debe ser registrado para que otra persona o usuario no pueda utilizarlo. Por el contrario, el hosting es donde se aloja nuestro sitio web; es ese espacio en el que almacenamos todos los archivos para que el sitio web pueda funcionar.
Dicho esto, cuando se contrata un servicio de hosting, se contrata el dominio, por un lado, y el alojamiento por el otro, aunque a veces puedan parecer lo mismo. Muchos proveedores de hosting ofrecen paquetes que incluyen ambos servicios. Del mismo modo, los usuarios más experimentados saben que pueden obtener estos servicios por separado, incluso de proveedores diferentes. También es importante mencionar que es posible tener varios dominios que apunten a un solo hosting.
Migración de hosting
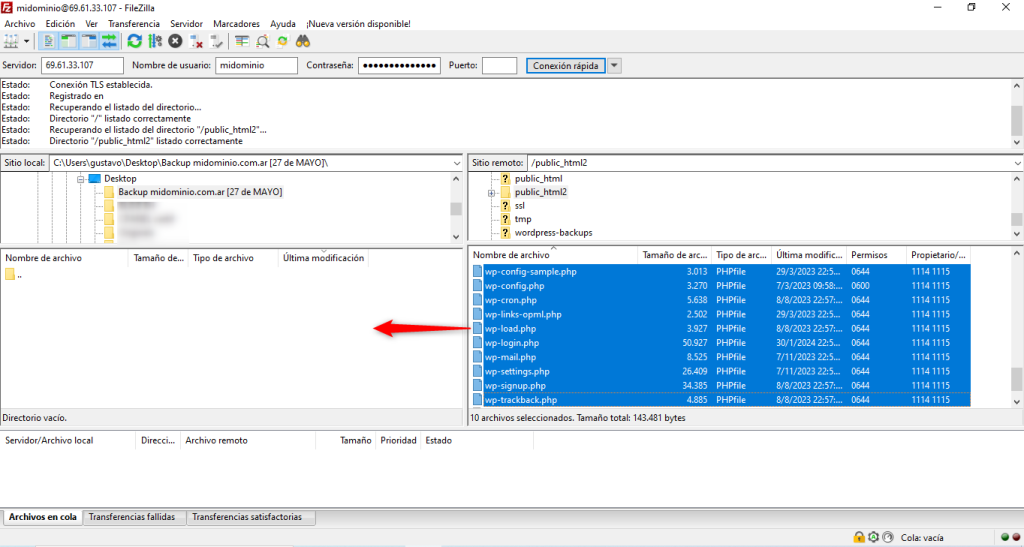
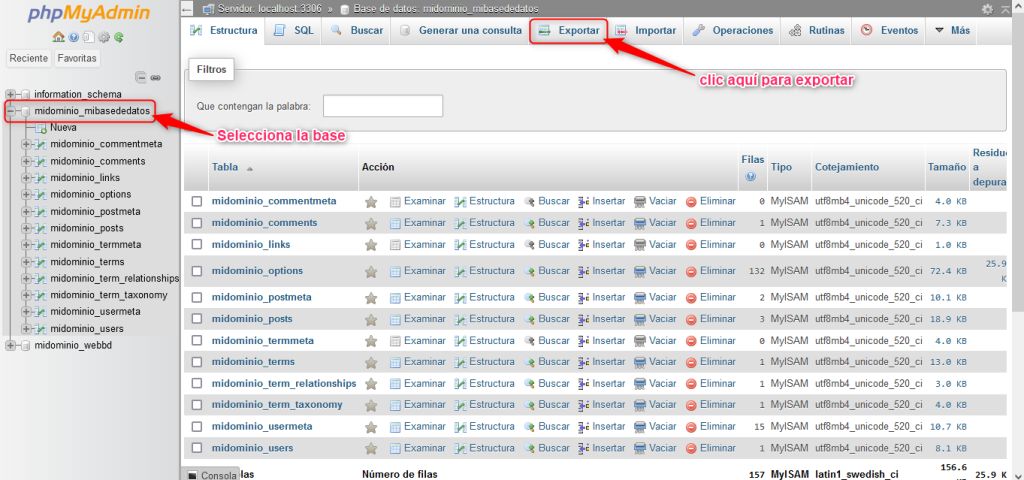
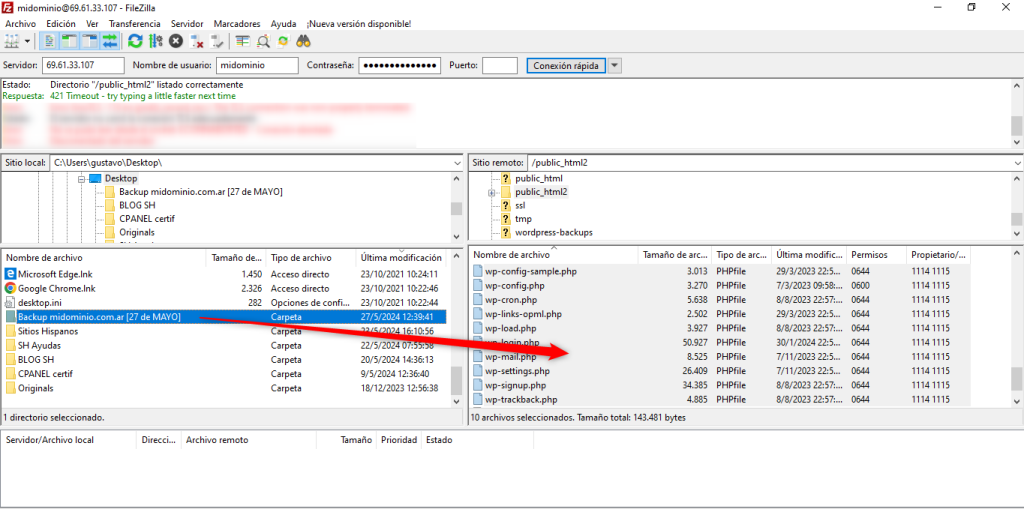
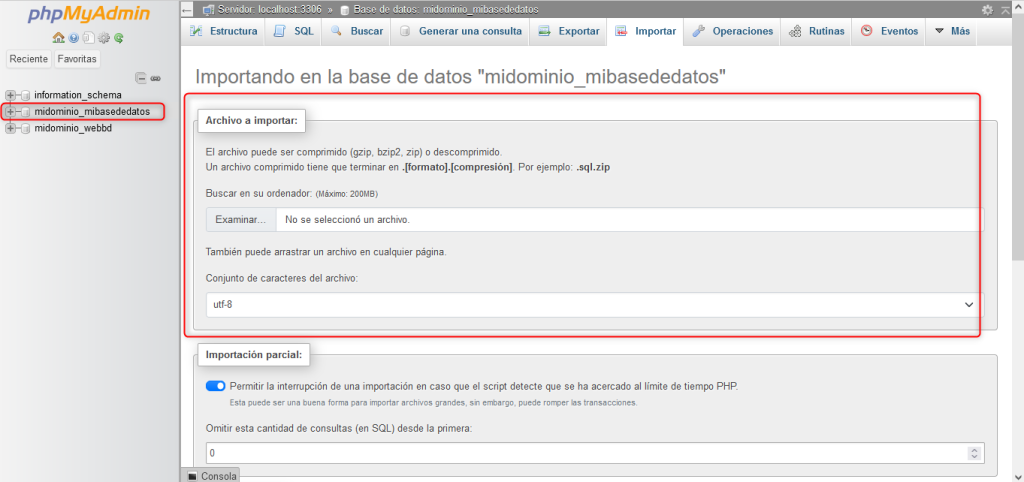
Una vez aclarado las terminologías anteriores, vamos a profundizar el tema de migraciones. Cuando se habla de migración se refiere a copiar los archivos de un proveedor de hosting a otro o también puede ser el caso de cambiarlo de servidor dentro del mismo proveedor. Un caso de esto para ejemplificar el porqué sucede esto es; digamos que los usuarios de un proveedor de hosting no están conformes con los precios, y encuentran que otro proveedor que ofrece las misma características por un poco menos o por el contrario, puede que ofrezcan más recursos por el mismo precio. Una vez contratado el servicio de hosting en otro proveedor, puede solicitar la migración de su sitio web al nuevo proveedor de alojamiento.
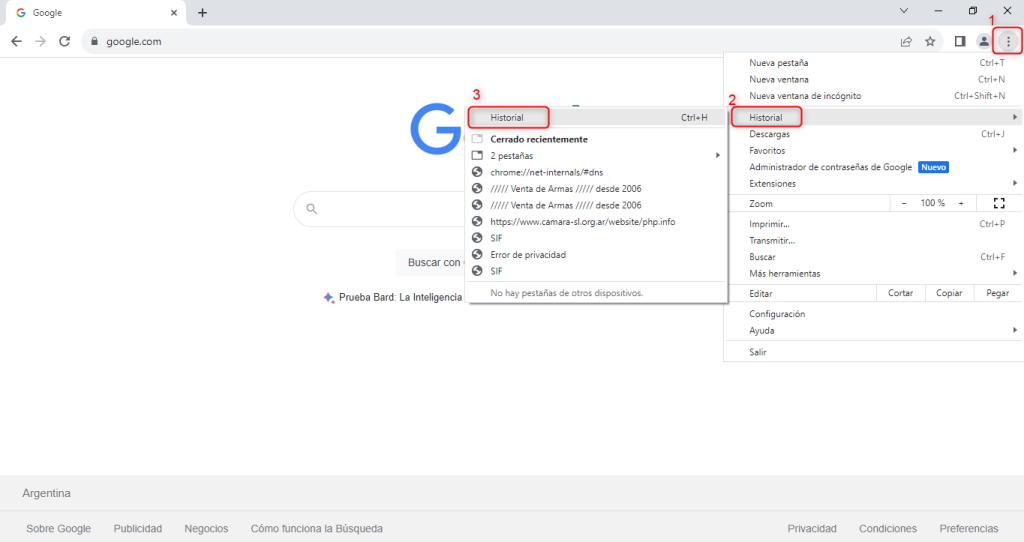
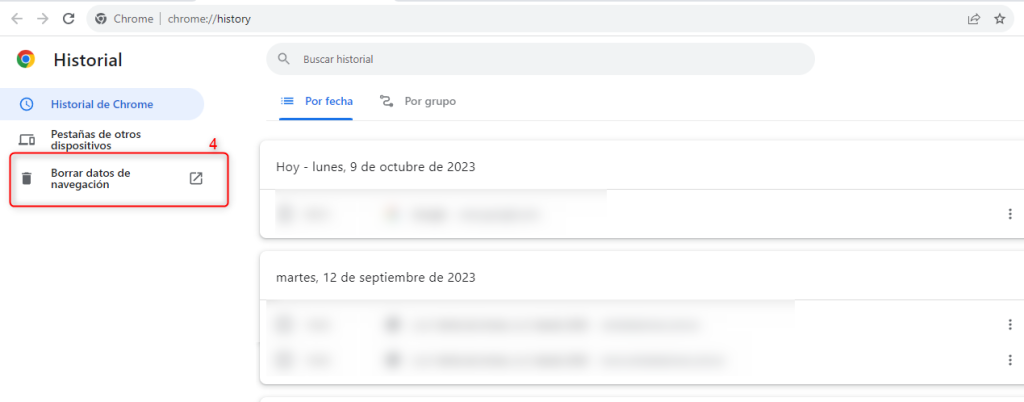
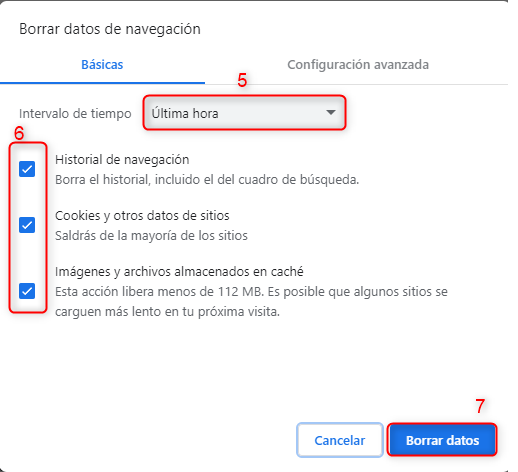
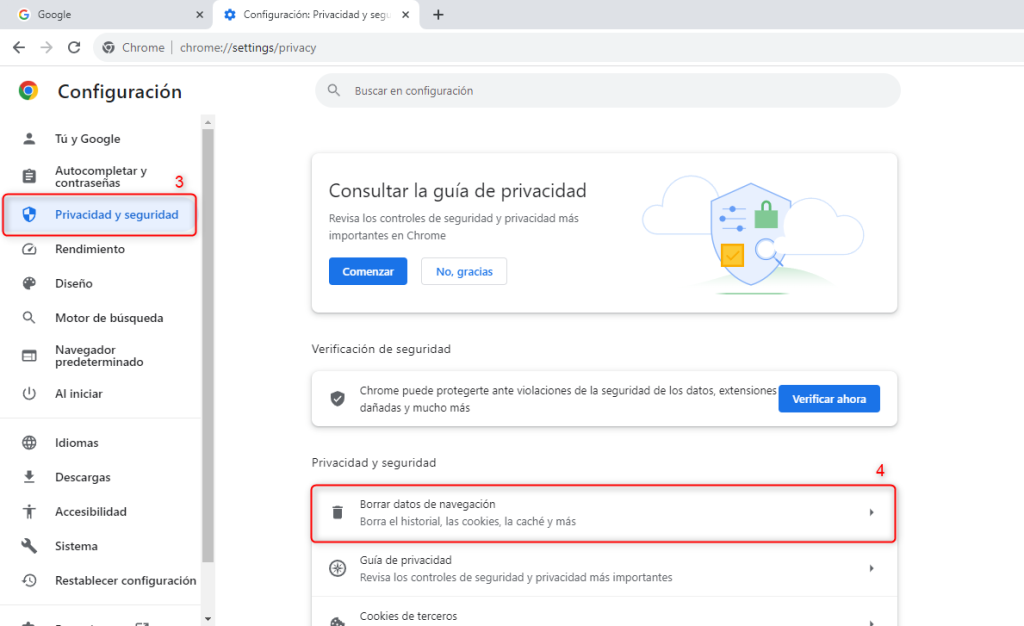
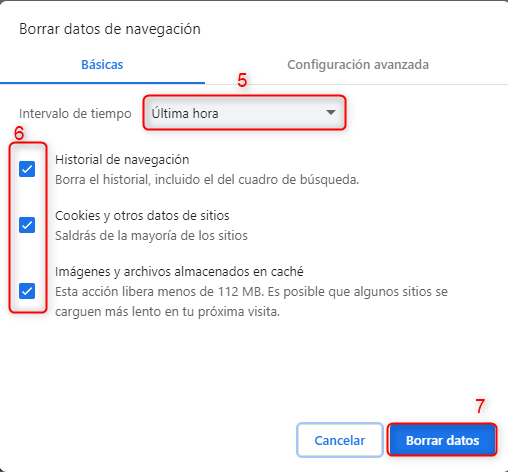
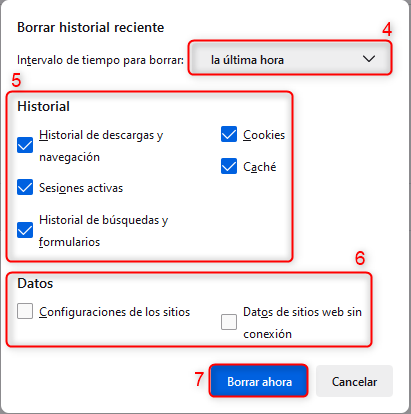
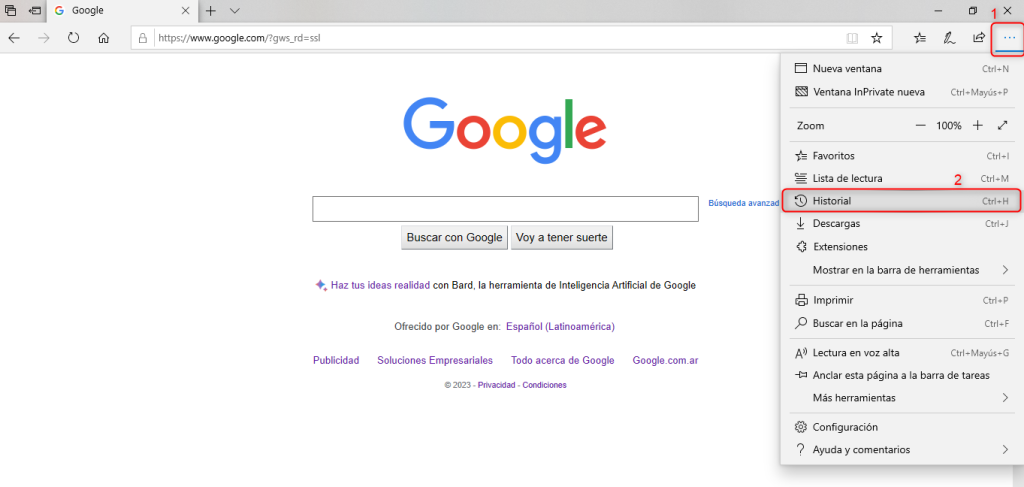
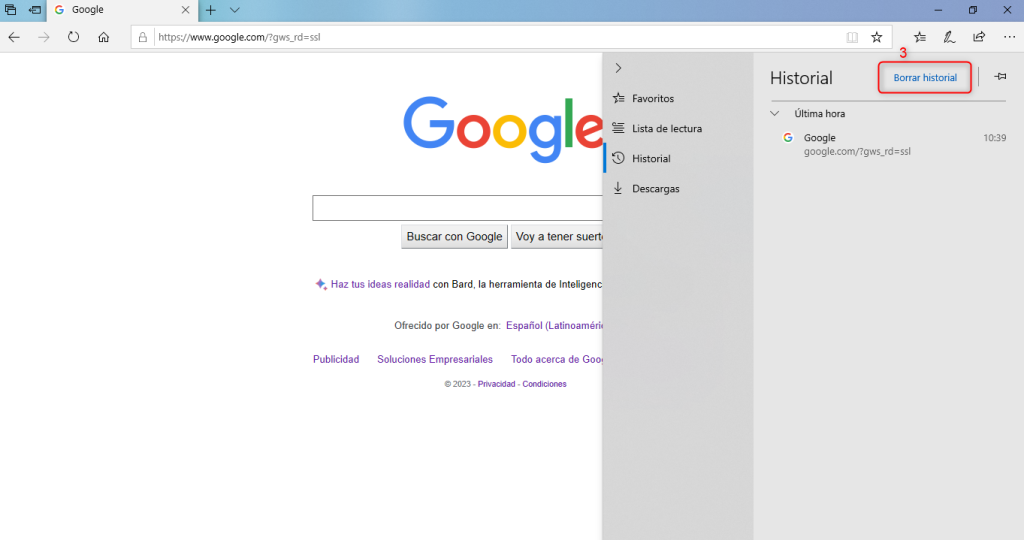
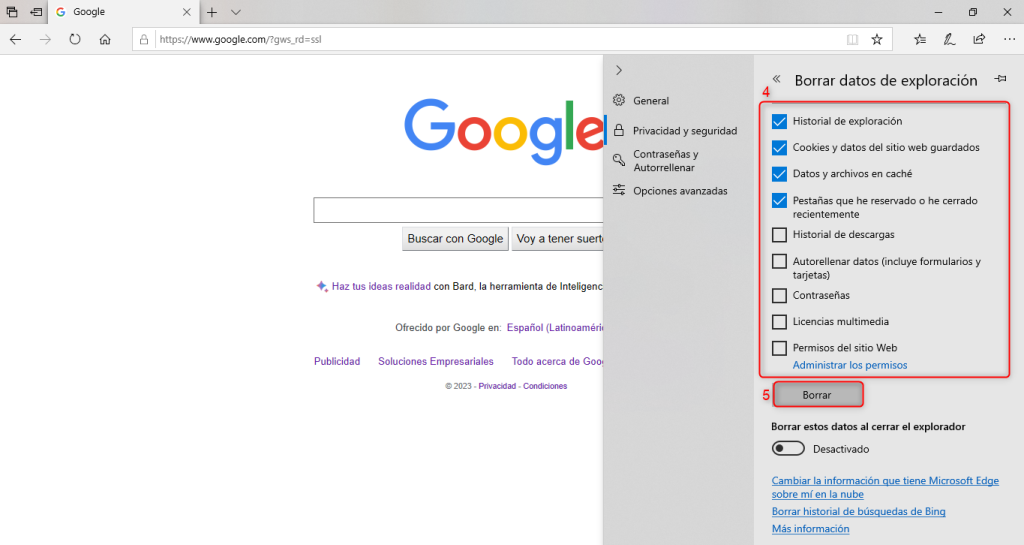
Es importante mencionar que antes de efectuar una migración siempre será necesario realizar una copia de seguridad completa de todos los archivos del sitio web, incluyendo la base de datos si es aplicable. Esto es fundamental en caso de que ocurra algún problema durante la migración.
También es aconsejable establecer un horario para la migración así se evita el impacto negativo en la audiencia de tu sitio web. Puedes considerar hacer la migración durante un período de menor actividad, como por ejemplo durante la noche o en el fin de semana.
En la gran mayoría de las migraciones luego de finalizar el proceso, se debe actualizar los registros DNS de tu dominio para apuntar al nuevo servidor de hosting. Esto es esencial para que el tráfico llegue al nuevo servidor una vez que se complete la migración.
Transferencia de dominio
A menudo, se tiende a pensar que cuando migramos un sitio web, automáticamente se transfiere su dominio. Sin embargo, esto no es del todo cierto. Como explicamos anteriormente, estos son dos servicios independientes. Cuando hablamos de transferir un dominio, nos referimos a trasladar la administración de nuestro nombre de dominio de un proveedor a otro. Esto es especialmente común en el caso de dominios con extensiones globales como .com, .net o .org.
Esta transferencia suele tener lugar por diversas razones, siendo una de las más comunes el costo del nombre de dominio ofrecido por un proveedor en comparación con otro. También es importante considerar la accesibilidad para pagar o abonar el dominio en moneda local, ya que esto puede facilitar la gestión y administración del dominio. Además, existen situaciones en las que los clientes desean unificar todos los servicios relacionados con su sitio web bajo un solo proveedor.
El proceso de transferencia de dominios implica desbloquear el dominio en su proveedor actual y obtener un código de autorización. Luego, deberá iniciar el proceso de transferencia en su nuevo proveedor, que generalmente implica ingresar el código de autorización y confirmar la transferencia.
Tenga en cuenta que una vez completada la transferencia, puede llevar algún tiempo (generalmente unas horas a un par de días) para que los cambios se propaguen por Internet y su sitio web esté plenamente funcional en su nuevo proveedor.
Para conocer más en detalle sobre transferencia de dominios, lo invitamos a leer: ¿Cómo transferir mi dominio?.
Esperamos que este artículo le haya ayudado a entender un poco el tema de migraciones de hosting y sobre transferencias de dominios.
Si te gustó este artículo, suscríbete a nuestro canal de YouTube para videos tutoriales de Hosting, prácticas y demás. También puede encontrarnos en Twitter, Facebook e Instagram.