Los errores 404 aparecen cuando un visitante intenta acceder a una página que no existe en tu sitio web. Esto puede suceder por enlaces rotos, URLs modificadas, contenido eliminado o errores de escritura en los enlaces.
Aunque un error 404 ocasional es normal, una gran cantidad de estos errores puede afectar negativamente la experiencia del usuario, el rastreo de los motores de búsqueda y el posicionamiento SEO de tu sitio en WordPress.
En esta guía actualizada aprenderás cómo recibir alertas automáticas por correo electrónico cada vez que se produzca un error 404 en tu sitio WordPress, además de conocer buenas prácticas para detectarlos y solucionarlos rápidamente.
¿Por qué es importante supervisar los errores 404?
Monitorear los errores 404 permite detectar problemas antes de que afecten a tus visitantes o al SEO del sitio. Algunas de las ventajas principales son:
- Mejorar la experiencia del usuario: Cuando un visitante encuentra una página inexistente, puede abandonar el sitio inmediatamente. Detectar y corregir estos errores ayuda a mantener una navegación fluida.
- Proteger el posicionamiento SEO: Motores de búsqueda como Google interpretan los enlaces rotos como señales de mala calidad o mantenimiento deficiente, especialmente si los errores son recurrentes.
- Detectar enlaces rotos internos: Muchas veces los errores 404 provienen de enlaces internos incorrectos después de migraciones, cambios de URLs o eliminación de contenido.
- Identificar ataques o exploraciones automáticas: Los bots maliciosos suelen intentar acceder a rutas inexistentes como
/wp-admin.oldo/phpmyadmin. Supervisar los errores 404 ayuda a detectar actividad sospechosa. - Reducir la tasa de rebote: Si corriges rápidamente las páginas inexistentes o aplicas redirecciones adecuadas, los usuarios permanecerán más tiempo en tu sitio.
Opción recomendada: Plugin 404 to 301 – Redirect, Log and Notify 404 Errors

Una de las formas más simples de recibir notificaciones de errores 404 es usando el plugin: 404 to 301 – Redirect, Log and Notify 404 Errors
Este plugin permite:
Consultar estadísticas e historial de errores.
- Registrar errores 404.
- Recibir alertas por correo electrónico.
- Configurar redirecciones automáticas.
- Filtrar bots y rastreadores.
Paso 1: Instalar el plugin
Desde el panel de administración de WordPress:
- Ve a Plugins > Añadir nuevo.
- Busca 404 to 301.
- Haz clic en Instalar.
- Luego selecciona Activar.
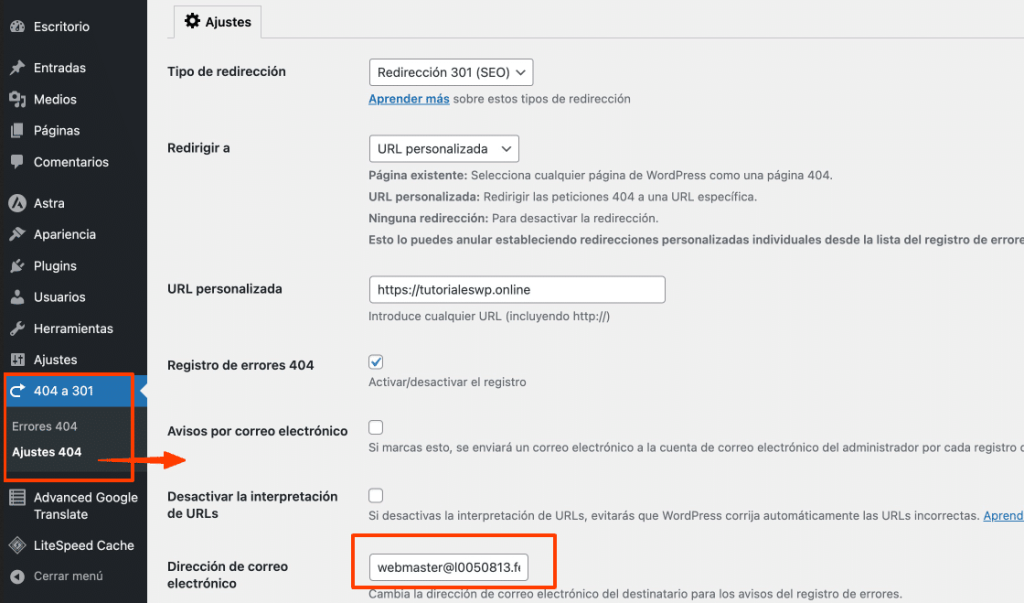
Paso 2: Configurar las alertas por correo electrónico
Una vez activado:
- Accede a Ajustes > 404 to 301.
- En la sección General Settings:
- Activa Enable 404 Logging.
- Activa Email Notifications.
- Introduce el correo donde deseas recibir las alertas.
- Guarda los cambios.
A partir de ese momento, WordPress podrá enviarte notificaciones cuando se detecten errores 404.
Funcionalidades adicionales del plugin 404 to 301
Además de las notificaciones, este plugin incluye herramientas útiles para gestionar los errores 404:
- Redirección automática: Permite redirigir a los usuarios a una página personalizada o similar, evitando que lleguen a una página de error.
- Historial de errores 404: Registra todos los errores detectados, ayudándote a identificar patrones y solucionar problemas recurrentes.
- Exclusión de bots: Filtra los errores generados por bots, asegurando que solo recibas alertas relacionadas con visitantes reales.
Configuraciones recomendadas
Excluir bots y crawlers
Actualmente, gran parte de los errores 404 provienen de bots automatizados y scanners de vulnerabilidades.
Por eso se recomienda activar:
- Exclude Bots
- Ignore Query Parameters
- Ignore Common WordPress Scans
Esto evita llenar tu correo con alertas irrelevantes.
Limitar la frecuencia de correos
En sitios con mucho tráfico, recibir un email por cada error 404 puede resultar excesivo.
Lo ideal es configurar:
- Resúmenes diarios.
- Resúmenes cada ciertas horas.
- Alertas únicamente para URLs críticas.
Verificar que WordPress pueda enviar correos
Muchos servidores bloquean o limitan el envío de correos PHP (mail()), especialmente en hosting compartido.
Para garantizar la entrega de notificaciones, se recomienda configurar SMTP usando plugins como:
Esto mejora notablemente la entregabilidad de las alertas.
Funciones útiles del plugin 404 to 301
Registro completo de errores
Permite ver:
- URL solicitada.
- Fecha y hora.
- IP del visitante.
- Referencia (referrer).
- Navegador utilizado.
Redirecciones automáticas
Puedes redirigir automáticamente:
- A la página de inicio.
- A una URL personalizada.
- A una página relacionada.
Historial de errores
Ayuda a detectar patrones repetitivos y enlaces rotos frecuentes.
Filtrado de bots
Reduce falsos positivos generados por rastreadores automáticos.
Alternativas recomendadas
Si buscas alternativas al plugin 404 to 301, estas opciones también pueden ayudarte:
- Redirection: Un plugin popular para gestionar redirecciones y recibir alertas de errores 404. Es ideal para mantener el SEO en buen estado.
- All In One WP Security & Firewall: Este plugin combina funciones de seguridad avanzadas con la capacidad de monitorear y recibir notificaciones de errores 404.
- Broken Link Checker: Excelente complemento para detectar, enlaces internos rotos, imágenes inexistentes y URLs externas caídas.
Cómo analizar y solucionar errores 404
Una vez configuradas las alertas, es importante abordar los errores 404 tan pronto como se detecten:
- Identifica la causa del error: Estos errores suelen generarse por cambios en las URLs o eliminación de contenido.
- Corrige enlaces rotos: Actualiza los enlaces internos que apunten a páginas inexistentes.
- Configura redirecciones: Usa herramientas como 404 to 301 o Redirection para redirigir URLs antiguas o eliminadas.
- Consulta el historial de errores: Utiliza el registro del plugin para identificar patrones y prevenir futuros problemas.
Buenas prácticas para evitar errores 404
Implementar las siguientes acciones puede ayudarte a minimizar la aparición de errores 404 en tu sitio:
- Crea redirecciones al modificar URLs: Siempre que cambies una URL, configura una redirección 301 para evitar interrupciones en la navegación.
- Monitorea enlaces regularmente: Usa herramientas como Broken Link Checker para detectar y reparar enlaces rotos.
- Mantén el mapa del sitio actualizado: Esto facilita la indexación por los motores de búsqueda y evita incluir páginas eliminadas.
- Diseña una página 404 personalizada: Proporciona enlaces útiles o una barra de búsqueda para mejorar la experiencia del usuario en caso de errores.
Recomendación adicional: monitoreo sin plugins
Si administras un VPS o servidor dedicado, también puedes detectar errores 404 directamente desde los logs del servidor web.
Por ejemplo:
- Apache:
access_log - Nginx:
access.log
Esto resulta útil para:
- Detectar ataques automáticos.
- Analizar patrones de tráfico.
- Reducir carga de plugins en WordPress.
Conclusión
Recibir alertas de errores 404 por correo electrónico es esencial para optimizar tu sitio WordPress, tanto en términos de SEO como de experiencia de usuario. Plugins como 404 to 301 o Redirection simplifican este proceso, ayudándote a gestionar y corregir errores de manera efectiva. Implementa estas recomendaciones para mantener un sitio funcional y bien posicionado, asegurando la satisfacción de tus visitantes.
Además, complementar estas herramientas con revisiones periódicas, redirecciones 301 y monitoreo desde el servidor ayudará a mantener tu sitio WordPress saludable, optimizado y libre de enlaces rotos.
Si te gustó este artículo, suscríbete a nuestro canal de YouTube para videos tutoriales de Hosting, prácticas y demás. También puede encontrarnos en X (Twitter), Facebook e Instagram.