Fortalecer la seguridad en la pantalla de inicio de sesión de WordPress es esencial para prevenir accesos no autorizados y proteger tu sitio. Aunque no existen plugins exclusivos para incorporar preguntas de seguridad en el inicio de sesión, es posible lograr un nivel de protección similar implementando la autenticación multifactor (MFA). Una opción recomendada es el plugin miniOrange Multi Factor Authentication, que permite integrar métodos como aplicaciones de autenticación, correos electrónicos, códigos y preguntas de seguridad personalizadas.
¿Por qué es importante añadir una capa adicional de seguridad en WordPress?
Incorporar una segunda capa de protección en el acceso a WordPress refuerza la seguridad contra ataques de fuerza bruta y accesos no deseados. La MFA, que puede incluir preguntas de seguridad personalizadas, asegura que únicamente los usuarios autorizados puedan ingresar, incluso en caso de que sus contraseñas sean vulneradas. Por esta razón, aquí te explicamos cómo añadir preguntas de seguridad para reforzar el acceso a tu sitio WordPress.
Paso 1: Instalar el plugin miniOrange Multi Factor Authentication

Para habilitar la autenticación multifactor en tu sitio WordPress, el primer paso es instalar el plugin miniOrange Multi Factor Authentication desde el repositorio oficial de WordPress. Sigue estos pasos:
- Ingresa al panel de administración de tu sitio WordPress.
- Dirígete a Plugins > Añadir nuevo.
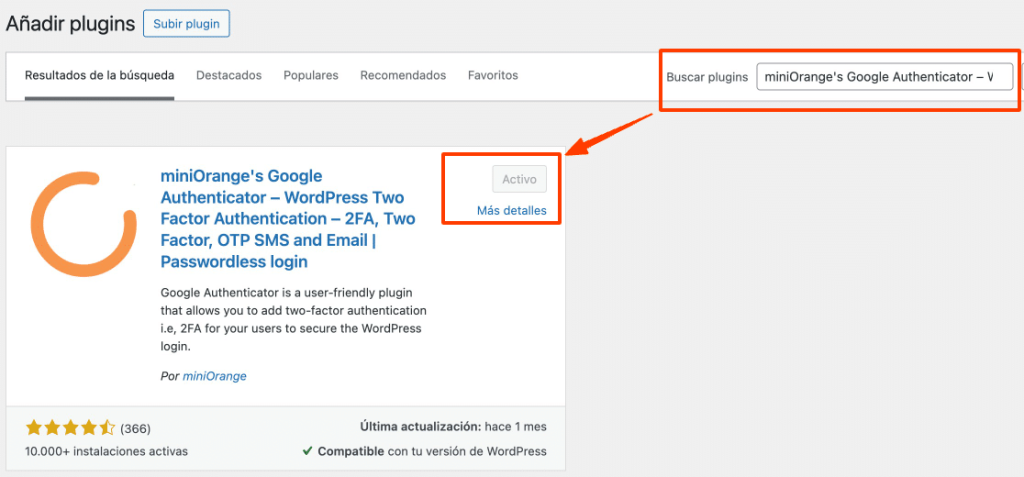
- En el buscador, escribe “miniOrange Multi Factor Authentication” y selecciona el plugin correspondiente.
- Haz clic en Instalar ahora y, una vez completada la instalación, selecciona Activar.
Paso 2: Configurar las opciones de autenticación multifactor
Tras activar el plugin, accede a la configuración para personalizar el método de autenticación que deseas implementar, incluyendo preguntas de seguridad. Para ello:
- En el panel de administración, selecciona miniOrange 2-Factor en el menú lateral.
- En la página de configuración, explora las diferentes opciones de autenticación disponibles, como:
- Aplicaciones de autenticación (como Google Authenticator).
- OTP por correo electrónico (código de un solo uso enviado por email).
- Preguntas de seguridad personalizadas.
- Verificación por SMS.
Para habilitar preguntas de seguridad, elige la opción Security Questions, sigue las instrucciones para configurarlas y activa este método de verificación. De esta manera, podrás reforzar la seguridad del inicio de sesión en tu sitio WordPress con preguntas personalizadas.
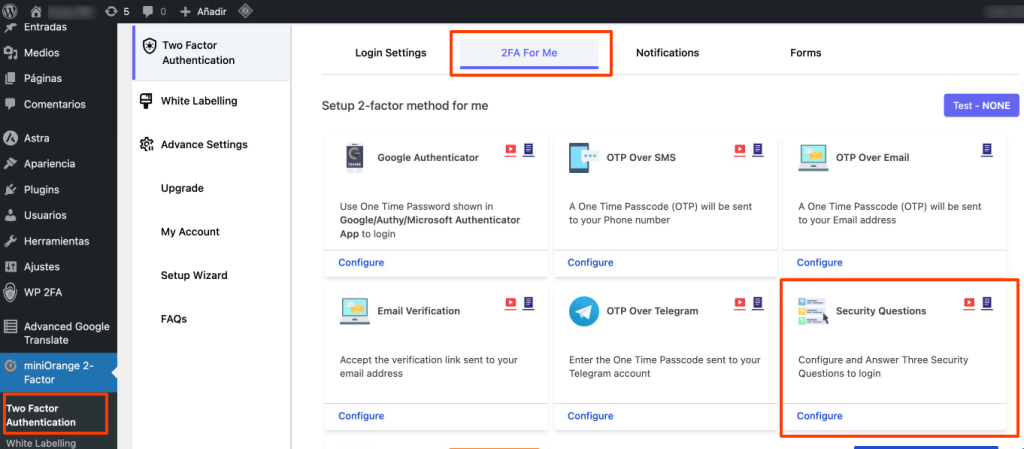
Paso 3: Personaliza las preguntas de seguridad
Configurar preguntas de seguridad para el inicio de sesión en WordPress es una medida recomendada para mejorar la protección de tu sitio. Sigue estos pasos para activarlas y personalizarlas:
- Dentro de la sección Security Questions del plugin, selecciona preguntas predeterminadas o crea tus propias preguntas personalizadas.
- Establece la cantidad de preguntas que los usuarios deberán responder y personaliza tanto las preguntas como las respuestas según lo necesites.
- Guarda los cambios para finalizar la configuración.
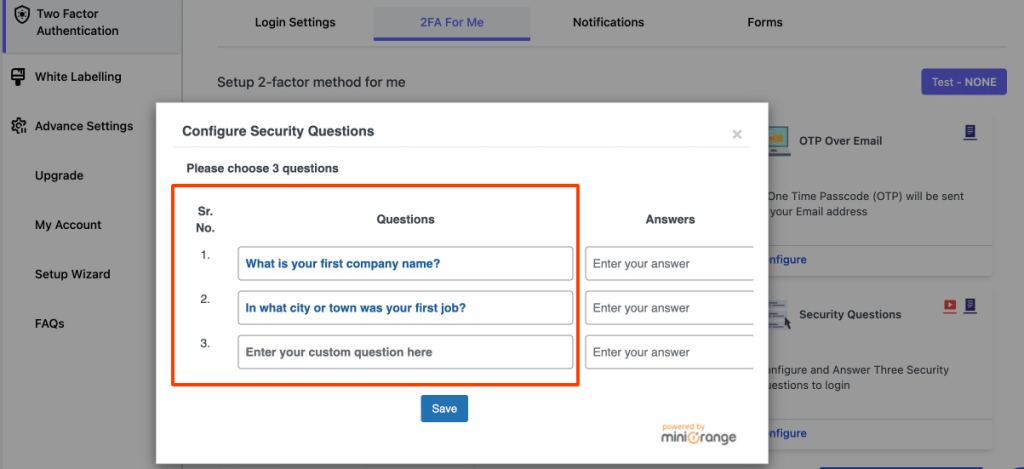
A partir de este momento, los usuarios deberán responder correctamente a estas preguntas para completar el proceso de inicio de sesión.
Paso 4: Asigna métodos de autenticación según los usuarios
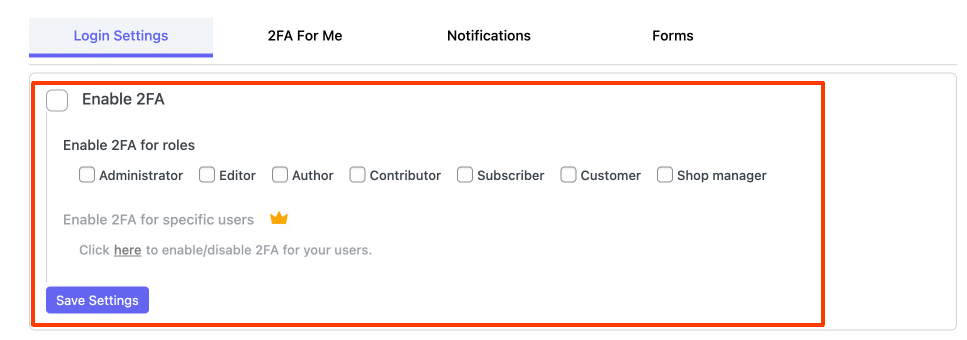
Además de implementar preguntas de seguridad, puedes configurar distintos métodos de autenticación para diferentes roles de usuario en WordPress. Por ejemplo, es posible habilitar la autenticación multifactor (MFA) solo para administradores y editores. Para hacerlo:
- Accede a miniOrange 2-Factor > Usuarios en el menú del panel de administración.
- En esta sección, asigna los métodos de autenticación requeridos a cada usuario según sus roles.
- Si deseas que todos los usuarios respondan preguntas de seguridad, asegúrate de habilitar esta opción para los roles correspondientes en la configuración del plugin.
Con estas configuraciones, puedes personalizar la seguridad de inicio de sesión en tu sitio WordPress de manera flexible y efectiva.
Paso 5: Verifica el funcionamiento de la autenticación multifactor
Una vez configuradas las preguntas de seguridad en el acceso a WordPress, es importante asegurarte de que todo opere correctamente. Sigue estos pasos para realizar una prueba:
- Cierra sesión en tu cuenta de administrador.
- Intenta iniciar sesión nuevamente y verifica que se muestre la pantalla de autenticación con la pregunta de seguridad u otro método configurado.
- Completa el proceso de verificación y asegúrate de que funciona sin inconvenientes.
Si encuentras problemas, revisa la configuración del plugin para confirmar que cada usuario tenga habilitada la autenticación multifactor (MFA).
Preguntas frecuentes sobre autenticación multifactor en WordPress
¿Qué hacer si un usuario olvida la respuesta a su pregunta de seguridad?
El administrador puede restablecer la autenticación desde el perfil del usuario en la sección de Usuarios o a través de la configuración del plugin miniOrange. Además, es posible configurar métodos de respaldo para este tipo de situaciones.
¿Es posible habilitar varios métodos de autenticación simultáneamente?
Sí, el plugin miniOrange permite configurar múltiples métodos de autenticación. Puedes ofrecer opciones como preguntas de seguridad, Google Authenticator o códigos enviados por correo electrónico para que los usuarios elijan.
¿Se puede desactivar temporalmente la autenticación multifactor?
Si es necesario, puedes desactivar temporalmente MFA desde la configuración del plugin en miniOrange 2-Factor o desactivando el plugin en la sección de Plugins.
Recomendaciones adicionales de seguridad para WordPress
Además de las preguntas de seguridad, considera implementar las siguientes medidas para mejorar la protección de tu sitio:
- Usa contraseñas robustas: Asegúrate de que todos los usuarios tengan contraseñas largas y complejas.
- Implementa un firewall y protección antimalware: Complementa la seguridad con herramientas como Wordfence para prevenir amenazas.
- Mantén todo actualizado: Asegúrate de instalar las actualizaciones de WordPress y los plugins regularmente para evitar vulnerabilidades.
Conclusión
Aunque añadir preguntas de seguridad en WordPress no es una práctica estándar, el plugin miniOrange Multi Factor Authentication te permite integrarlas dentro de un enfoque moderno de autenticación multifactor. Este método no solo incluye preguntas de seguridad, sino también opciones como códigos de un solo uso y autenticación con aplicaciones móviles. Siguiendo estos pasos, puedes fortalecer significativamente la seguridad de tu sitio y proteger la información de tus usuarios de manera efectiva.
Si te gustó este artículo, suscríbete a nuestro canal de YouTube para videos tutoriales de Hosting, prácticas y demás. También puede encontrarnos en X (Twitter), Facebook e Instagram, además de LinkedIn.