La memoria caché del navegador es una función que acelera la navegación en línea al almacenar en caché las imágenes y los archivos de los sitios web que visitas con frecuencia. Sin embargo, a veces puede ser necesario borrar la memoria caché del navegador para resolver problemas de visualización o para proteger tu privacidad. Esto no solo acelera el proceso de carga, sino que también optimiza el uso de ancho de banda.
En este artículo, te mostraremos cómo borrar la memoria caché del navegador en los navegadores más populares.
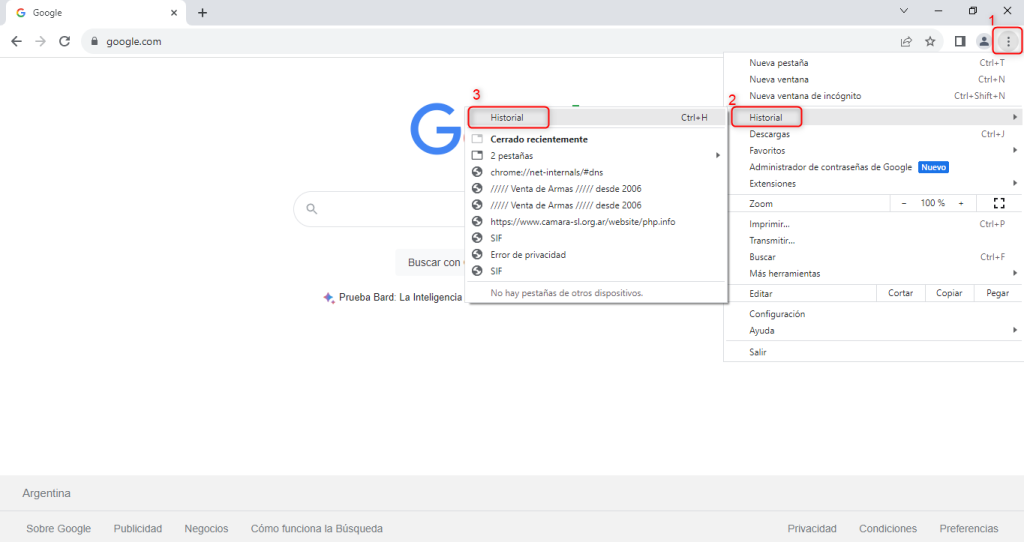
Cómo borrar la memoria caché del navegador en Google Chrome:
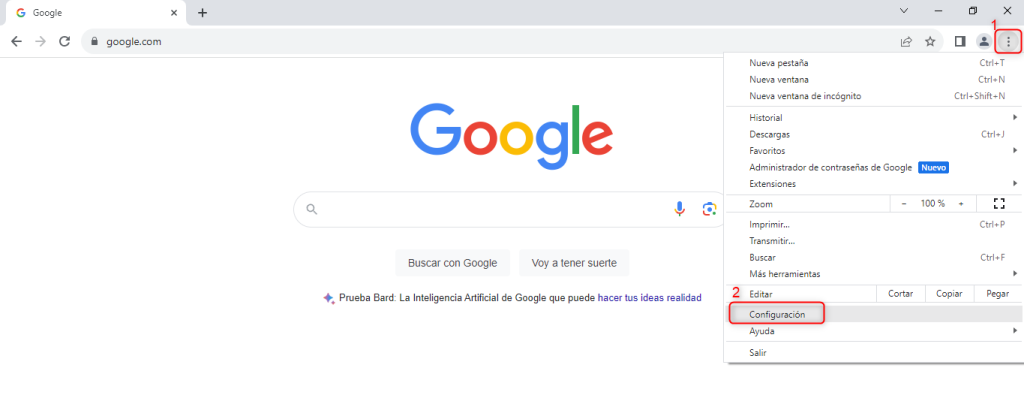
- Abre Google Chrome y haz clic en los tres puntos verticales en la esquina superior derecha de la pantalla.
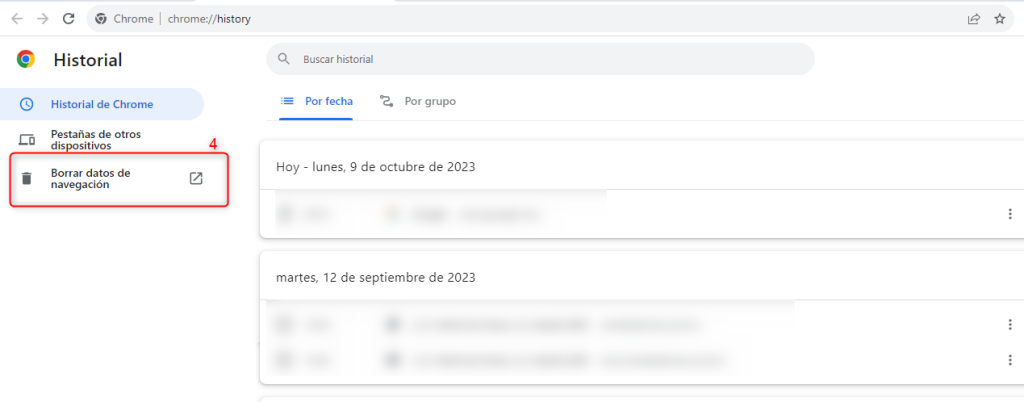
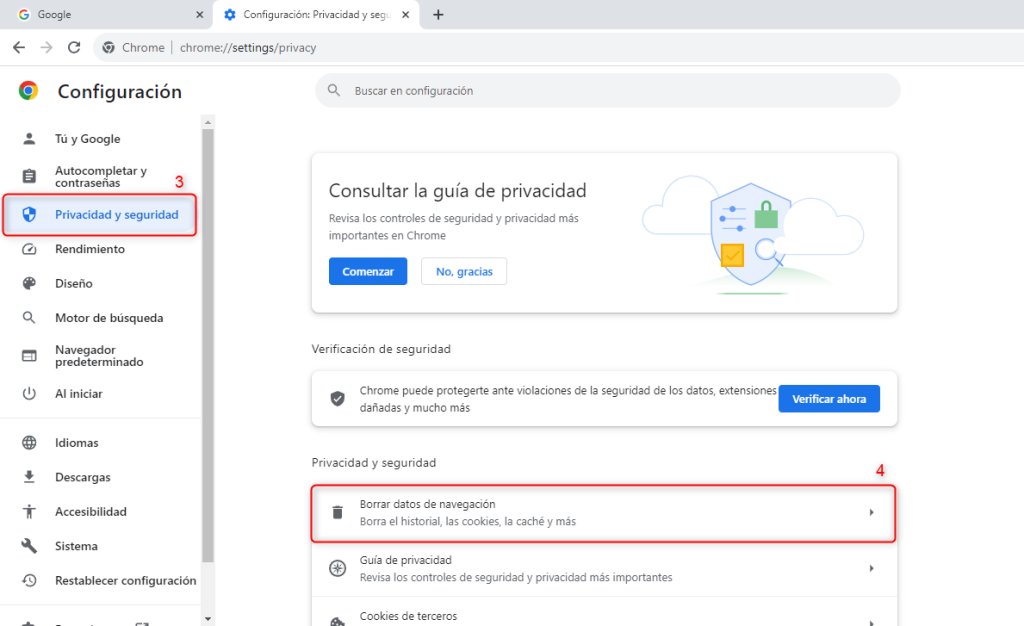
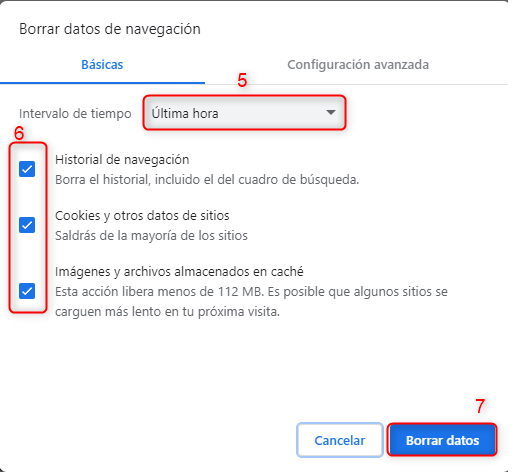
- Selecciona “Más herramientas” y luego “Borrar datos de navegación”.
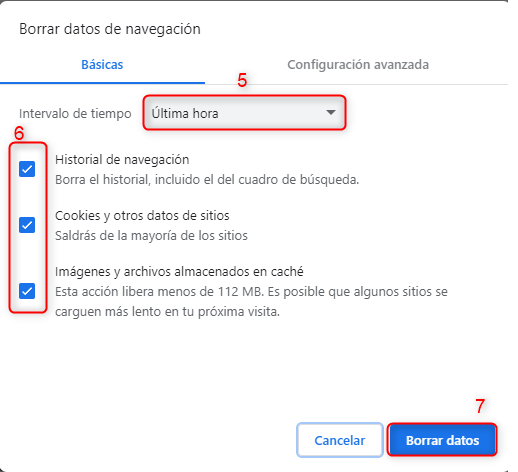
- Selecciona el período de tiempo que deseas borrar y asegúrate de que la casilla “Imágenes y archivos almacenados en caché” esté marcada.
- Haz clic en “Borrar datos”.
Cómo borrar la memoria caché del navegador en Mozilla Firefox:
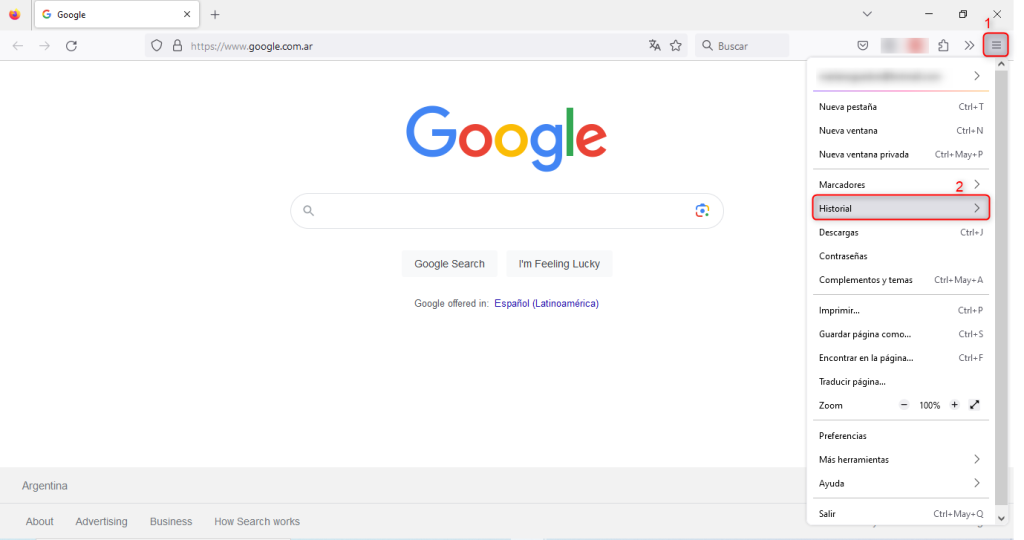
- Abre Mozilla Firefox y haz clic en el botón de menú en la esquina superior derecha de la pantalla.
- Selecciona “Opciones” y luego “Privacidad y seguridad”.
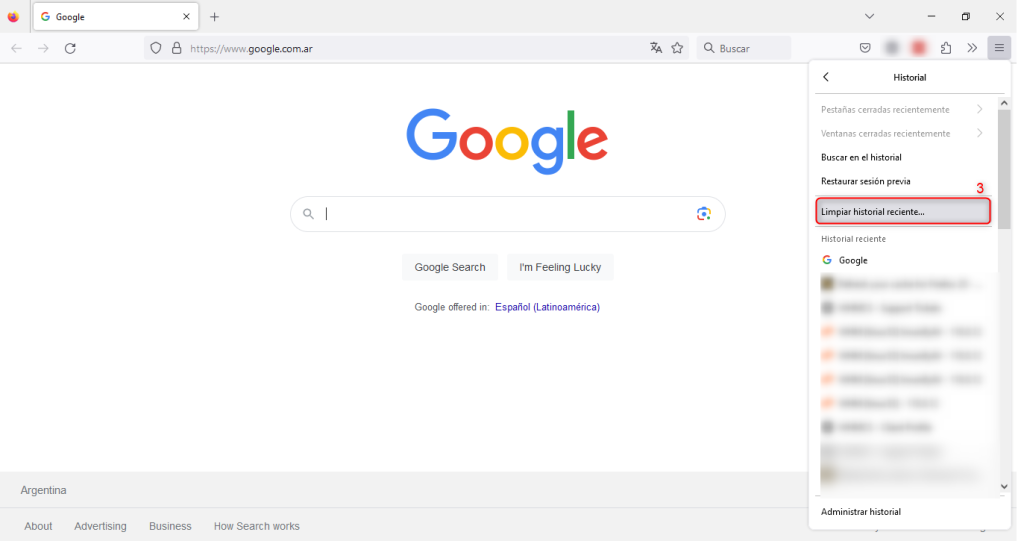
- Desplázate hacia abajo hasta “Historial” y haz clic en “Eliminar datos de navegación”.
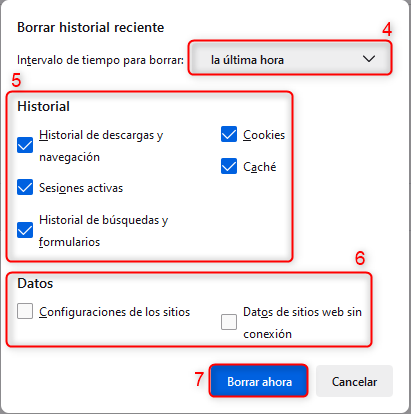
- Selecciona el período de tiempo que deseas borrar y asegúrate de que la casilla “Caché” esté marcada.
- Haz clic en “Eliminar ahora”.
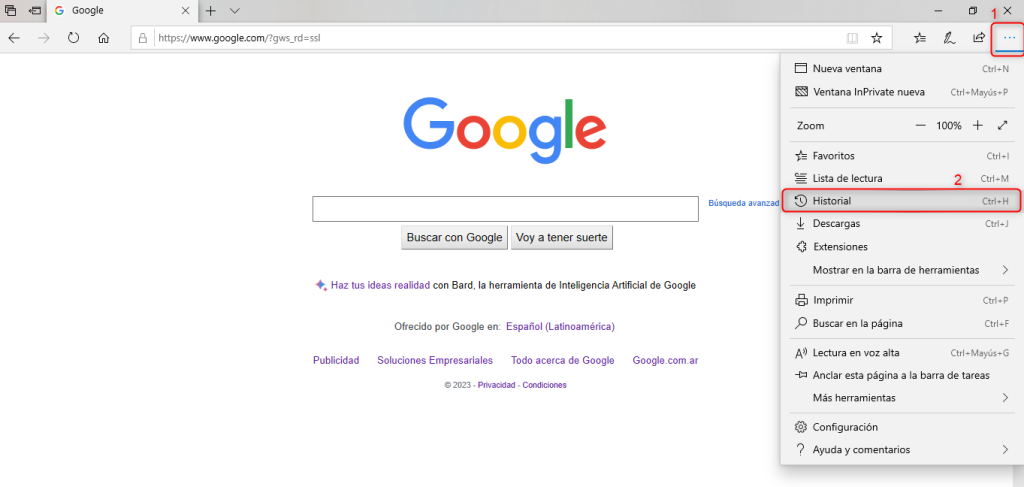
Cómo borrar la memoria caché del navegador en Microsoft Edge:
- Abre Microsoft Edge y haz clic en los tres puntos horizontales en la esquina superior derecha de la pantalla.
- Selecciona “Configuración” y luego “Privacidad, búsqueda y servicios”.
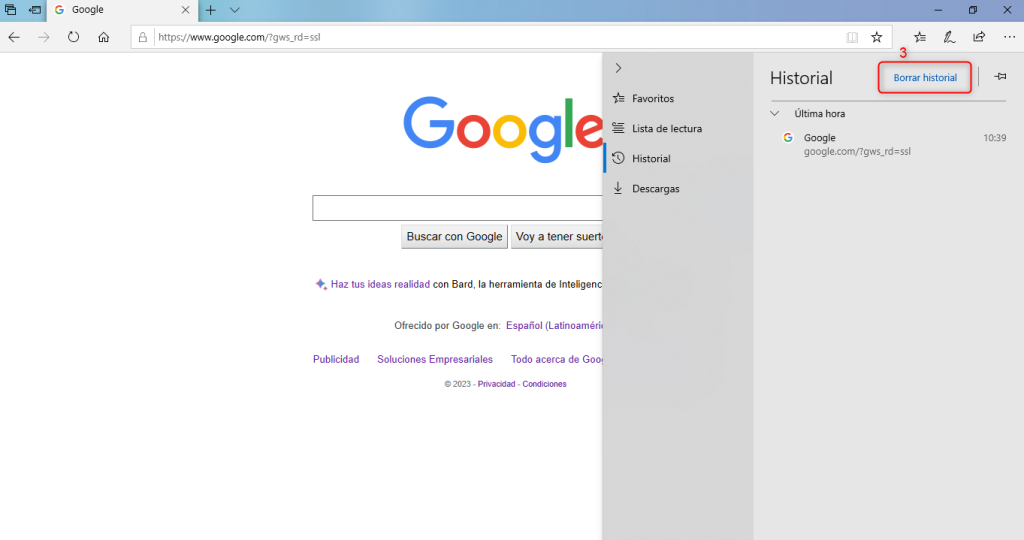
- Desplázate hacia abajo hasta “Eliminar datos de navegación” y haz clic en “Elegir qué borrar”.
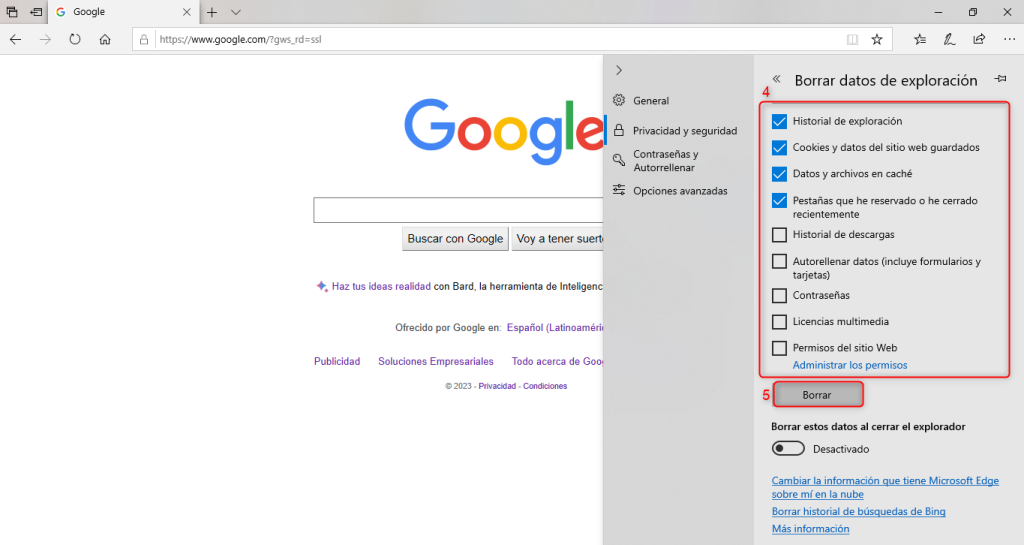
- Selecciona el período de tiempo que deseas borrar y asegúrate de que la casilla “Imágenes y archivos almacenados en caché” esté marcada.
- Haz clic en “Borrar ahora”.
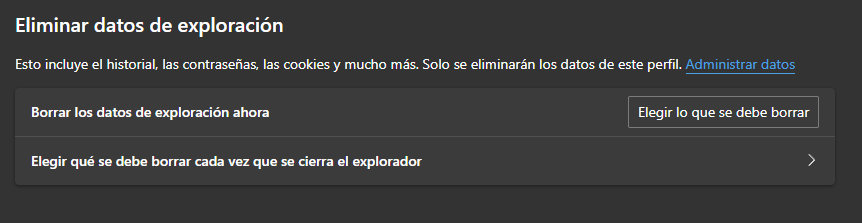
Vista de Microsoft Edge.
No hay necesidad de preocuparse por eliminar los datos almacenados en caché, ya que no se eliminarán ni los datos personales ni la información relevante. La memoria caché del navegador simplemente almacena copias de archivos de páginas web que se han visitado anteriormente, lo que permite que el navegador cargue estos archivos más rápidamente en futuras visitas.
Borrar la memoria caché del navegador es una tarea sencilla que puede ayudarte a resolver problemas de visualización y a proteger tu privacidad en línea. Si tienes dificultades para borrar la memoria caché del navegador en tu navegador preferido, asegúrate de consultar la documentación oficial o buscar tutoriales en línea. ¡Espero que este artículo te sea útil! Si necesitas más ayuda, no dudes en preguntar.
También le podría interesar nuestro artículo: ¿Cómo refrescar la caché de tu navegador?
Si te gustó este artículo, suscríbete a nuestro canal de YouTube para videos tutoriales de Hosting, prácticas y demás. También puede encontrarnos en X (Twitter), Facebook e Instagram, además de LinkedIn.